
3秒利用谷歌文档Google Sheets 做爬虫抓取任意网站指定内容
2019年11月2日
| 标签:
:
项目背景和挑战
有时候需要使用爬虫批量抓取一系列网址的指定位置,并且导入到excel,一般的思路是使用python,但是需要懂编程语言 并且假设运行环境 并且学习保存文件 和乱码 要累死人,使用桌面端软件如八爪鱼 火车头等软件是简单,但是需要安装软件并且保存的数据也是有格式要求,如果是少量的数据 特地去下载安装也比较费事,
解决思路
有没有一种比较简单的
不需要任何编程基础,
不需要安装任何软件,
只要点几下鼠标就能做出来爬虫 抓取大量网站的内容 并且把需要的数据保存到excel
答案是有的 只需要3秒,复制2次就可以抓取任意网站的任意内容
操作方法
其实就利用谷歌的产品谷歌文档 google docs中google sheets,它其实是一个在线的excel网站
但是有一个函数功能可以抓取网页,并且能指定抓取的方法(xpath) 达到精准抓取的目的
当然整个解决方案的前提是
你要能扶墙到国外,访问谷歌文档的google sheets,使用他的importxml 函数
1,使用谷歌浏览器 chrome 选择你要抓取的网页的内容 点击右键 选择
如图所示 打开https://news.163.com/18/1203/10/E23JJ2DN0001875P.html 网易新闻
选中标题右键检查后
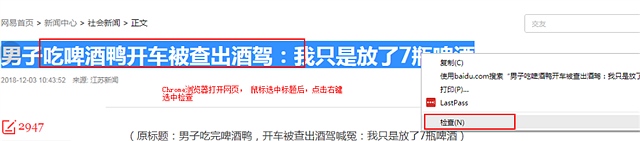
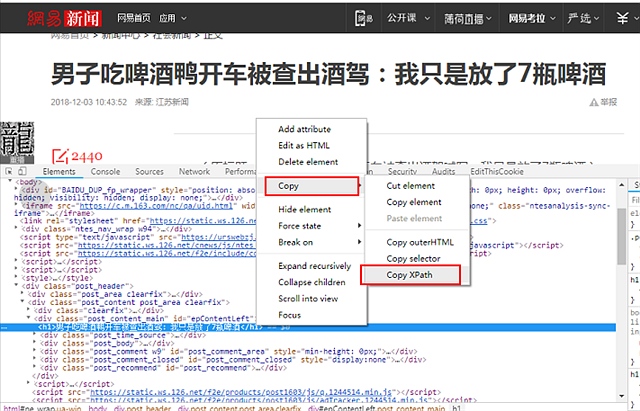
2 在chrome打开的开发工具里面选择标题的代码 选择 复制 – xpath
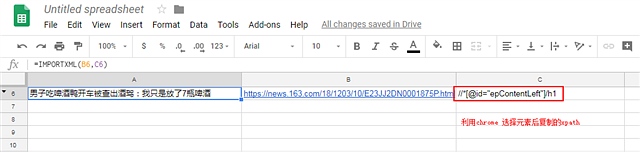
3 打开谷歌文档的谷歌sheets 可以新建一个 https://docs.google.com/spreadsheets/u/0/
输入公式,这里可以把抓取的网址放在一个单元格, 复制过来的xpath放在另外一个单元格
使用公式importxml 输入这2个单元格的地址即可 可以看到 该公式会抓取页面后 根据xpath的路径把文字抓取来 放到单元格中
再换一个例子 看看我们抓取新闻来源
1,打开网址http://money.163.com/18/1203/10/E23I0L6D002580S6.html 选择新闻来源文字右键检查 在打开的开发者工具中复制 xpath
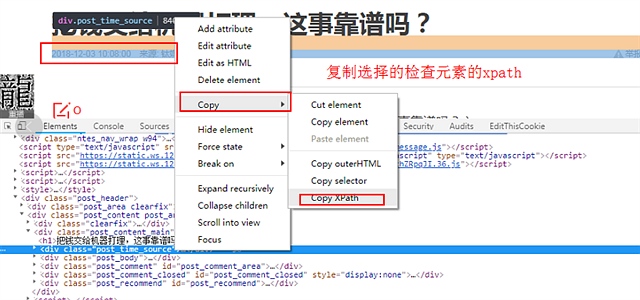
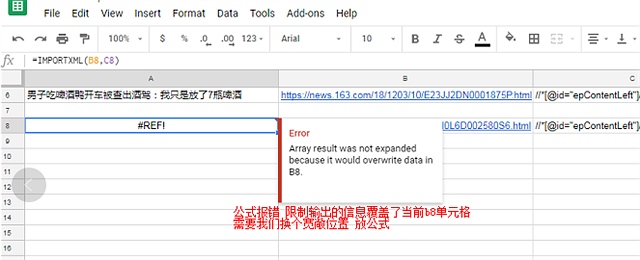
2 在google sheets中 插入xpath公式 发现公式无法运行 原因是公式的输出会覆盖别的单元格 我们需要换个位置放公式
3我们修改下公式的位置放到别的地方
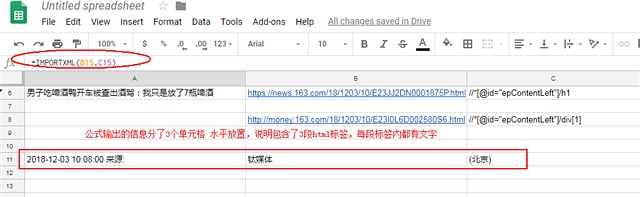
发现输出的信息分到3个单元格 原因是因为抓取的文字是包含在3个不同的html标签 所以会被分成3个单元格存放
发现输出的信息分到3个单元格 原因是因为抓取的文字是包含在3个不同的html标签 所以会被分成3个单元格存放
这里有2个解决办法
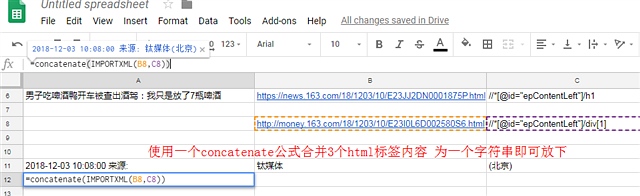
4.1 解决google sheets中的importxml 输出多个单元格的方法1,再使用一个concatenate公式 强行把输出的信息写成一个字符串
4.2解决google sheets中的importxml 输出多个单元格的方法2,
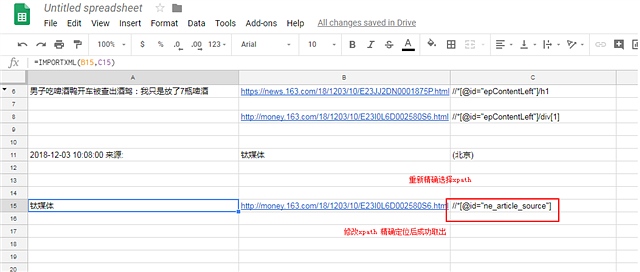
重新选择xpath ,精确选择具体的元素 重新修改xpath

4.2.1 这里可以看到精确修改后的xpath就只会输出一个元素 不需要加公司 更加精确(推荐)
如果我们要抓取的是非文字信息如超链接的地址
只需要把xpath里面的信息 //*[@id=”ne_article_source”] 换成了//*[@id=”ne_article_source”]/@href
就可以抓取这个a标签的href属性的值 是不是很简单
写在最后
本文介绍了一种迅速简单的办法根据页面的URL和对应元素的xpath 利用谷歌文档来当爬虫 抓取的例子
方法比较简单 容易上手
关于xpath的详细介绍 可以看这篇 xpath语法入门到实战
但有的网址会有反爬机制 需要指定浏览器访问头信息 和其他信息 就不能用这种了
并且如果我们想要抓取列表信息,如一个页面有20个新闻标题以及对应的url或者百度的搜索结果
页面 我们要抓取前100个网址结果来比对 查询seo排名(后面会讲) 这个方法就不适用了
针对使用importxml 抓取多个结果的方法 会另外写一篇来讲解
项目背景和挑战
有时候需要使用爬虫批量抓取一系列网址的指定位置,并且导入到excel,一般的思路是使用python,但是需要懂编程语言 并且假设运行环境 并且学习保存文件 和乱码 要累死人,使用桌面端软件如八爪鱼 火车头等软件是简单,但是需要安装软件并且保存的数据也是有格式要求,如果是少量的数据 特地去下载安装也比较费事,
解决思路
有没有一种比较简单的
不需要任何编程基础,
不需要安装任何软件,
只要点几下鼠标就能做出来爬虫 抓取大量网站的内容 并且把需要的数据保存到excel
答案是有的 只需要3秒,复制2次就可以抓取任意网站的任意内容
操作方法
其实就利用谷歌的产品谷歌文档 google docs中google sheets,它其实是一个在线的excel网站
但是有一个函数功能可以抓取网页,并且能指定抓取的方法(xpath) 达到精准抓取的目的
当然整个解决方案的前提是
你要能扶墙到国外,访问谷歌文档的google sheets,使用他的importxml 函数
1,使用谷歌浏览器 chrome 选择你要抓取的网页的内容 点击右键 选择
如图所示 打开https://news.163.com/18/1203/10/E23JJ2DN0001875P.html 网易新闻
选中标题右键检查后
2 在chrome打开的开发工具里面选择标题的代码 选择 复制 – xpath
3 打开谷歌文档的谷歌sheets 可以新建一个 https://docs.google.com/spreadsheets/u/0/
输入公式,这里可以把抓取的网址放在一个单元格, 复制过来的xpath放在另外一个单元格
使用公式importxml 输入这2个单元格的地址即可 可以看到 该公式会抓取页面后 根据xpath的路径把文字抓取来 放到单元格中
再换一个例子 看看我们抓取新闻来源
1,打开网址http://money.163.com/18/1203/10/E23I0L6D002580S6.html 选择新闻来源文字右键检查 在打开的开发者工具中复制 xpath
2 在google sheets中 插入xpath公式 发现公式无法运行 原因是公式的输出会覆盖别的单元格 我们需要换个位置放公式
3我们修改下公式的位置放到别的地方
发现输出的信息分到3个单元格 原因是因为抓取的文字是包含在3个不同的html标签 所以会被分成3个单元格存放
发现输出的信息分到3个单元格 原因是因为抓取的文字是包含在3个不同的html标签 所以会被分成3个单元格存放
这里有2个解决办法
4.1 解决google sheets中的importxml 输出多个单元格的方法1,再使用一个concatenate公式 强行把输出的信息写成一个字符串
4.2解决google sheets中的importxml 输出多个单元格的方法2,
重新选择xpath ,精确选择具体的元素 重新修改xpath
4.2.1 这里可以看到精确修改后的xpath就只会输出一个元素 不需要加公司 更加精确(推荐)
如果我们要抓取的是非文字信息如超链接的地址
只需要把xpath里面的信息 //*[@id=”ne_article_source”] 换成了//*[@id=”ne_article_source”]/@href
就可以抓取这个a标签的href属性的值 是不是很简单
写在最后
本文介绍了一种迅速简单的办法根据页面的URL和对应元素的xpath 利用谷歌文档来当爬虫 抓取的例子
方法比较简单 容易上手
关于xpath的详细介绍 可以看这篇 xpath语法入门到实战
但有的网址会有反爬机制 需要指定浏览器访问头信息 和其他信息 就不能用这种了
并且如果我们想要抓取列表信息,如一个页面有20个新闻标题以及对应的url或者百度的搜索结果
页面 我们要抓取前100个网址结果来比对 查询seo排名(后面会讲) 这个方法就不适用了
针对使用importxml 抓取多个结果的方法 会另外写一篇来讲解
发表评论
| Trackback
