
下载网站全部链接的页面内容并导出到excel筛查是否包含敏感词-利用免费软件抓取和分析亲测可用
2019年11月10日
| 标签:
项目目的
有一个客户的网站上有上万的页面,我们需要对所有页面进行扫描并且分析是否包含敏感词,避免被搜索引擎降权和违规风险
项目背景
客户提供了一个xml版本的 sitemap的文件,包含网站的全部URL
关于如何获得网站的全部url 可以参考这边文章 免费sitemap 工具生成10万页面XML格式网站地图
思路分析
可用利用excel简单过滤,即可得到所有网站URL,大概一万多个页面,需要通过工具或者写代码的方式抓取页面的内容,并且结合分析每个页面的内容是否包含敏感词库,所以可以分3个步骤来完成
1,获取网页的所有内容,放到excel的一列中,每行第一个单元格放url,第2个单元格放页面所有可见内容,第3个单元格用来判断是否包含敏感词
2,把敏感词库放在excel的另外一个sheet中,合并一列
3,利用公式,遍历网站的内容,并且每个页面的内容去匹配判断是否包含敏感词库里每一行结果
实施细节
Part1, 获取页面内容,
我们本来使用python来抓取页面,但是考虑到需要大量页面的抓取,需要考虑的因素比较多,从0开始写代码 时间成本太长,需要些各种异常情况判断,如301,302,404 ,502等,并且通过python抓取的内容,需要存放在csv中,这需要额外去增加读写csv的代码,在没有熟悉成熟的框架的情况,该方法不合适(主要没实际掌握如何使用爬虫框架,只会简单语法),于是相当利用网站现场有的工具来爬取页面,免费的用的比较久的网页爬虫软件,推荐使用火车头抓取工具,老品牌,以前学习过,类似的工具应该也有,访问网址http://www.locoy.com,下载最新版本,免费版本有些限制,如不能添加抓取内容的高级规则比如正则过滤等,还有抓取的数据不能使用mysql,也不支持导出为excel,不过后面会有办法解决
下载安装好火车头爬虫后,使用抓取向导,记住使用根据url来抓取,
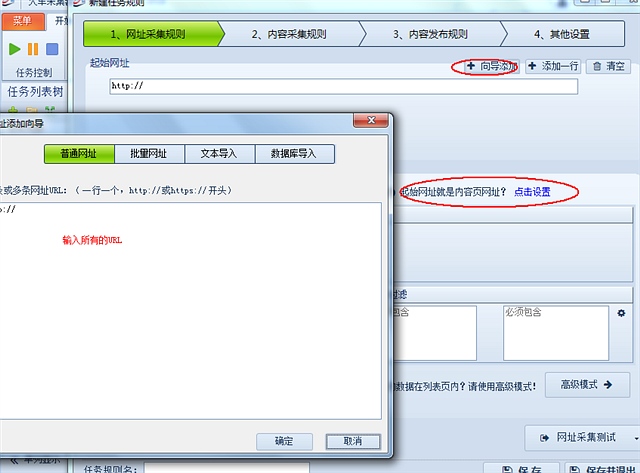
然后设定提供的url是内容页(否则会打开你提供的url吧里面所有的url都抓取,按就不是一万个页面,是好几万)然后设置抓取内容规则,
主要先使用body 开头以及body结尾
再添加字符串前缀补上一个<标签
再使用去除html
再替换所有的空格
既可以得到全部网站文字
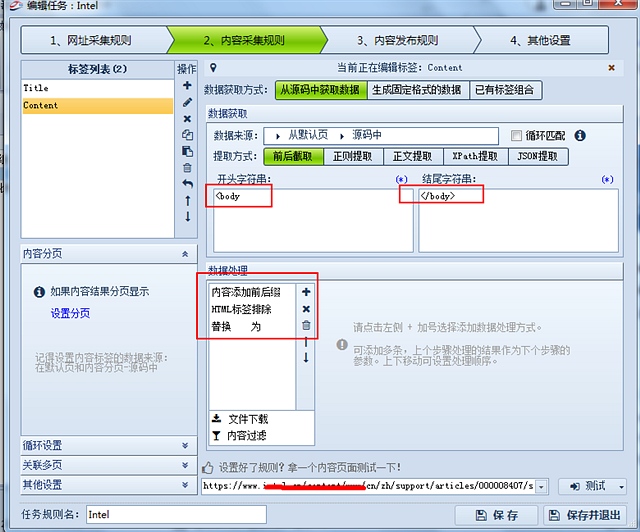
设置好爬取的速度,3秒打开一个页面然后开2个线程,同时开2个页面比较好
大概20分钟就可以把1w个页面全部抓取好
part2, 将火车头的数据导出数据到excel
我们使用的是免费的火车头版本,是不能导出数据,查询得知,她的数据文件名后缀是db3,既为sqlite格式的
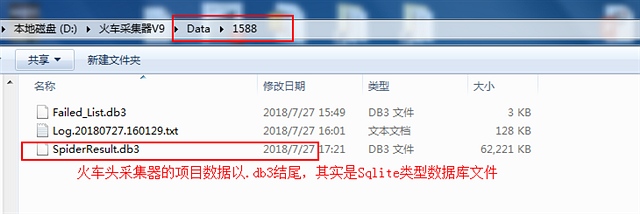
然后我们走了很多弯路去吧db3的文件转换为excel,先使用sqlitetoexcel,根本不好用
然后使用sqlite expert也无法打开,很多软件是收费版本,无法导出
最后才知道一个波兰的良心软件 sqlite studio
https://sqlitestudio.pl/index.rvt
这个比较好,可以支持打开db3文件并且导出为csv
然后我打开以后是乱码,没关系 使用记事本打开 另存为utf8
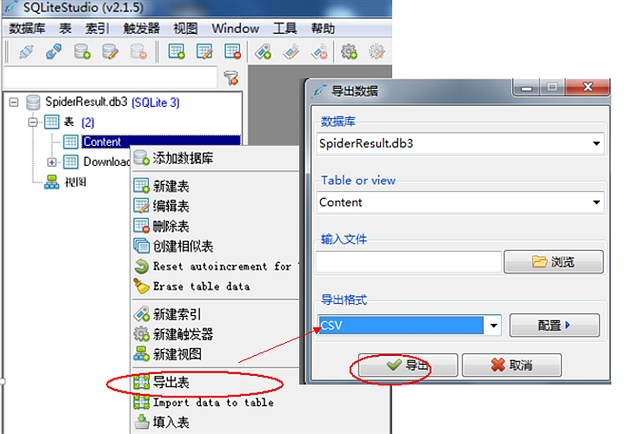
然后就可以复制到excel中
至此,即可完成抓取整站内容到excel的工作
接下来就是简单的excel公式通过小找到去匹配关键词库,是否包含即可
excel的公式方法在前面有讲到
http://cotine.blog.hexun.com/115744120_d.html
使用的是模糊匹配(大匹配小)
项目目的
有一个客户的网站上有上万的页面,我们需要对所有页面进行扫描并且分析是否包含敏感词,避免被搜索引擎降权和违规风险
项目背景
客户提供了一个xml版本的 sitemap的文件,包含网站的全部URL
关于如何获得网站的全部url 可以参考这边文章 免费sitemap 工具生成10万页面XML格式网站地图
思路分析
可用利用excel简单过滤,即可得到所有网站URL,大概一万多个页面,需要通过工具或者写代码的方式抓取页面的内容,并且结合分析每个页面的内容是否包含敏感词库,所以可以分3个步骤来完成
1,获取网页的所有内容,放到excel的一列中,每行第一个单元格放url,第2个单元格放页面所有可见内容,第3个单元格用来判断是否包含敏感词
2,把敏感词库放在excel的另外一个sheet中,合并一列
3,利用公式,遍历网站的内容,并且每个页面的内容去匹配判断是否包含敏感词库里每一行结果
实施细节
Part1, 获取页面内容,
我们本来使用python来抓取页面,但是考虑到需要大量页面的抓取,需要考虑的因素比较多,从0开始写代码 时间成本太长,需要些各种异常情况判断,如301,302,404 ,502等,并且通过python抓取的内容,需要存放在csv中,这需要额外去增加读写csv的代码,在没有熟悉成熟的框架的情况,该方法不合适(主要没实际掌握如何使用爬虫框架,只会简单语法),于是相当利用网站现场有的工具来爬取页面,免费的用的比较久的网页爬虫软件,推荐使用火车头抓取工具,老品牌,以前学习过,类似的工具应该也有,访问网址http://www.locoy.com,下载最新版本,免费版本有些限制,如不能添加抓取内容的高级规则比如正则过滤等,还有抓取的数据不能使用mysql,也不支持导出为excel,不过后面会有办法解决
下载安装好火车头爬虫后,使用抓取向导,记住使用根据url来抓取,
然后设定提供的url是内容页(否则会打开你提供的url吧里面所有的url都抓取,按就不是一万个页面,是好几万)然后设置抓取内容规则,
主要先使用body 开头以及body结尾
再添加字符串前缀补上一个<标签
再使用去除html
再替换所有的空格
既可以得到全部网站文字
设置好爬取的速度,3秒打开一个页面然后开2个线程,同时开2个页面比较好
大概20分钟就可以把1w个页面全部抓取好
part2, 将火车头的数据导出数据到excel
我们使用的是免费的火车头版本,是不能导出数据,查询得知,她的数据文件名后缀是db3,既为sqlite格式的
然后我们走了很多弯路去吧db3的文件转换为excel,先使用sqlitetoexcel,根本不好用
然后使用sqlite expert也无法打开,很多软件是收费版本,无法导出
最后才知道一个波兰的良心软件 sqlite studio
https://sqlitestudio.pl/index.rvt
这个比较好,可以支持打开db3文件并且导出为csv
然后我打开以后是乱码,没关系 使用记事本打开 另存为utf8
然后就可以复制到excel中
至此,即可完成抓取整站内容到excel的工作
接下来就是简单的excel公式通过小找到去匹配关键词库,是否包含即可
excel的公式方法在前面有讲到
http://cotine.blog.hexun.com/115744120_d.html
使用的是模糊匹配(大匹配小)
发表评论
| Trackback
